



In this blog, we are going to talk about Kubernetes architecture in detail. We are going to look at two types of nodes that Kubernetes operates on. One is the master and another is a slave. We are going to go through the basic concepts n how Kubernetes works and how the cluster is self-managed, self-healing and automated, and how we should operate the Kubernetes cluster so that we end up having less manual effort.

The main component of kubernetes is the worker node/server and each node will have multiple application pods with containers running on that node. The way kubernetes does this is by using three processes that must be installed on every node that are used to manage and schedule the pods. So nodes are the cluster server that actually does the work, that's why sometimes called worker nodes.
Worker Nodes Components
The first process that runs on every worker node is the container runtime such as docker, containerD etc. As application pods have containers running inside a container runtime needs to be installed on every node, But the process that actually schedules those pods and containers is the kubelet. Kubelet interacts with both the container and the node. So basically kubelet is responsible for taking configuration and actually running a pod or starting a pod within a container inside and then assigning resources. So kubernetes cluster is made of many worker nodes which must have container runtime and kubelet services installed.
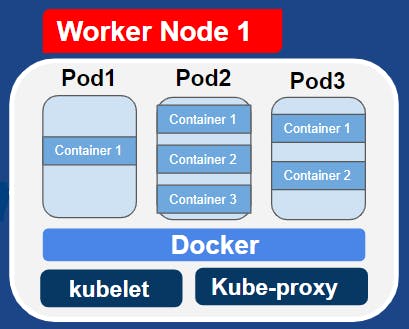
So the next thing is if there are many worker nodes how do they communicate with each other, So the answer is via services(which we will look at in upcoming blogs). So the third process that is responsible for forwarding request from services to ports is the Kube proxy which is also needs to be installed in every worker node. The kube proxy has actually intelligent forwarding logic that makes sure that the communication also works in a performant way.
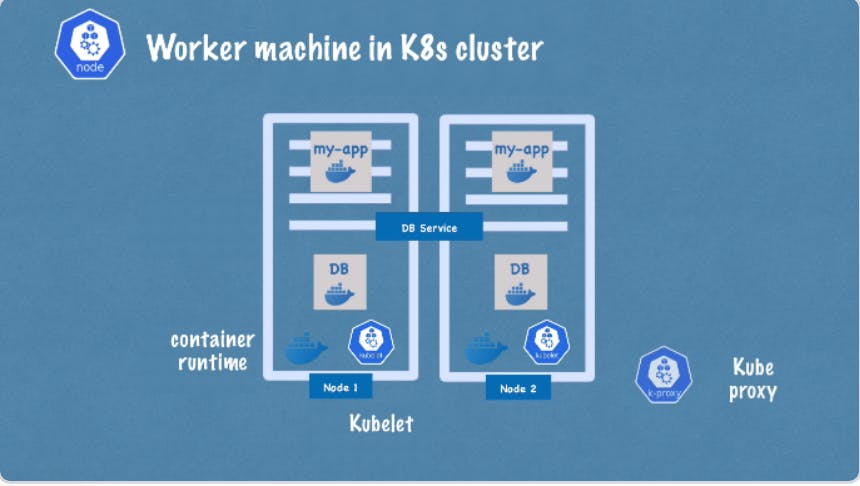
For example, if my app replica is requesting database instead of service just randomly forwarding any request to replicas it will forward it to the replica that is running in the same node as the pod present in the same node that made the request, this is to avoid the network overhead of sending the request to another node.
So to conclude kubelet and kube-proxy must be installed on every kubernetes worker node along with an independent container runtime for kubernetes cluster to function properly.
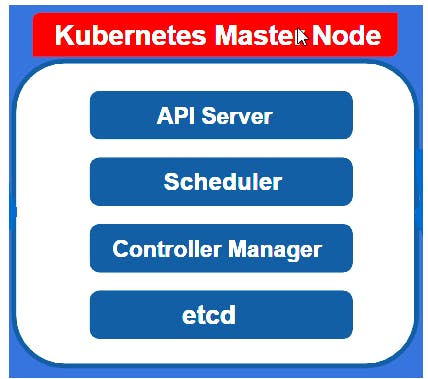
Here comes the next question how to interact with the cluster, who decides on which node a new app pod or db pod should be scheduled or if a replica pod dies who actually monitors it and reschedule or restarts it? So the answer is there is another node present in a cluster called the master node. So there are basically four component or processes that runs inside the master node and these four things control the cluster state and worker node as well.
Master Node Components
So the first component or process is the API Server-
So when someone tries to deploy a new application into a kubernetes cluster, the user interacts with the API server using some client. It's like a cluster gateway that gets the initial request for any updates into the cluster or even queries from the cluster. So when the user wants to schedule new pods, deploy a new app or create a new service the user has to talk to the API server on the master node. The API server validates the request and if everything is fine, then it will forward other processes in order to process the request. It is also used to query the status of the deployments or the cluster health.
The second component/ process is the Scheduler -
So if a request is sent to the API Server to create a new pod, after the API server validates it will hand over to the scheduler to the application pod on one of the worker nodes also instead of just putting the pod in any of the worker nodes, the scheduler is quite intelligent to decide on which specific node the next pod will be scheduled. So what it does is it will look at the request and see how much resources is required for the application pod such as CPU, ram and it will go through the worker nodes and see if the required resources is available on each of them and if it says that the node has most resources available it will schedule the pod on that node, So the imp note is that the scheduler just decides on which node the new pod will be scheduled and the process that actually does the scheduling that starts the pod in the container is the kubelet. So it gets request from the scheduler and executes the request.
The third component/ process is the Controller Manager -
It is one of the important component because of what happens when the pod dies on any worker node, there must be a way to restart or reschedule the pods as soon as possible. So the controller manager detects the changes like crashes of the pods, So when pods die controller manager detects and tries to recover the cluster state as soon as possible. So what it does is it requests to the scheduler to reschedule those dead pods. So the same cycle happens with the scheduler starting from resource calculation, in which worker node will restart the pod and requests the corresponding kubelet of the worker node.
The fourth component/ process is the ETCD -
So it is a key-value store of the cluster state. It works as the brain of the cluster, so it means it saves all the details such as when a new pod gets rescheduled or when a pod dies etc. These are saved in a key-value pair. It is also called the cluster brain because of its mechanism with the scheduler, controller manager works because of data. So let's take an example how does the scheduler knows what resources are available on each worker node or how does the CM knows that a cluster state is changed?
What is not stored in ETCD is the actual application data. For example, if a database is running inside the cluster the data will be stored somewhere else not in the ETCD.
So we got the gist of what processes/components are present in the worker and master nodes. The master is more important, but they have fewer loads of work, so they need fewer resources whereas worker nodes do the actual job of running pods with containers inside so they need more resources.
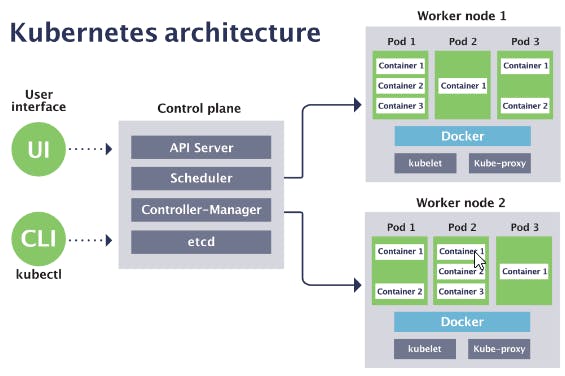
Here is the full kubernetes architecture. I hope you all liked the blog and if there is something more that I can add or improve do comment on the same.
So till then see you all in my next blog and do follow me for more. Thank you.